Joint Space-Time Video Segmentation and Analysis
Team: M. Ristivojevic, J. Konrad
Collaborators: M. Barlaud, F. Precioso, University of Nice, France
Funding: National Science Foundation (CISE-CCR-SPS, International Collaboration USA-Frrance)
Status: Completed (2001-2006)
Background: Traditional video processing methods use two image frames at a time to analyze such dynamics as motion, occlusions, etc. This does not allow to incorporate temporal continuity constraints on the estimated quantities, e.g., motion labels, occlusion labels, and thus the final estimates are often incoherent in time.
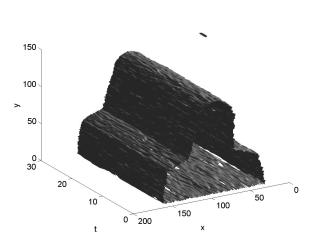
Summary: We explored a new framework that is based on joint treatment of many image frames (e.g., 20-30). A form of joint space-time processing, this framework is essentially three-dimensional (3-D) since its domain is the x-y-t space of image sequences. This approach results in more reliable video segmentation, detection of occlusion effects and identification of various dynamic events. In particular, we developed a video segmentation method that is based on an active-surface model and level-set solution. Applied to both synthetic and natural image sequences this method results in object tunnels in the x-y-t space, that we have used successfully to identify certain occlusion events and measure time instants of object occlusions, disappearance, entry, etc.
Publications:
- J. Konrad and M. Ristivojević, “Joint space-time image sequence segmentation based on volume competition and level sets,” in Proc. IEEE Int. Conf. Image Processing, vol. 1, pp. 573-576, Sept. 2002.
- J. Konrad and M. Ristivojević, “Video segmentation and occlusion detection over multiple frames,” in Proc. SPIE Image and Video Communications and Process., vol. 5022, pp. 377-388, Jan. 2003.
- M. Ristivojević and J. Konrad, “Joint space-time motion-based video segmentation and occlusion detection using multi-phase level sets,” in Proc. SPIE Visual Communications and Image Process., vol. 5308, pp. 156-167, Jan. 2004.
- M. Ristivojević and J. Konrad, “Joint space-time image sequence segmentation: object tunnels and occlusion volumes,” in Proc. IEEE Int. Conf. Acoustics Speech Signal Processing, vol. III, pp. 9-12, May 2004.
- M. Ristivojević and J. Konrad, “Space-time image sequence analysis: object tunnels and occlusion volumes,” in IEEE Trans. Image Process., vol. 15, pp. 364-376, Feb. 2006.
- M. Ristivojević and J. Konrad, “Multi-frame motion detection for active/unstable cameras,” in Proc. Brazilian Symp. on Computer Graphics and Image Proc., Oct. 2009.