Privacy-Preserving Action Recognition at Very Low Spatial and Temporal Resolutions
Team: J. Dai, J.Wu, B. Saghafi, J. Konrad, P. Ishwar
Funding: National Science Foundation (Lighting Enabled Systems and Applications ERC)
Status: Ongoing (2014-…)
Background: It is expected that a smart room of the future will naturally “interact” with its occupants. For example, lighting, heating/cooling, window blinds will be adjusted differently for watching a movie in the evening than for a family meal at a table during the day. A different intensity and spectrum of light will be produced when one gets up from bed in the morning (brighter light with higher blue content to wake up) than when one needs to visit a bathroom at night (dimmer light with more yellowish content). Today, reliable methods for activity recognition from video cameras exist. In many scenarios, however, cameras cannot be used to recognize activities on account of privacy issues, for example in a bathroom. Clearly, sensing methodologies and recognition algorithms are needed to recognize activity with high certainty but without violating occupant’s privacy.
Summary: This project aims to explore the trade-off between action recognition performance, number of cameras, and spatial and temporal resolution in a smart-room environment.

Study 1: Semi-simulated data – real movements, simulated appearance
As it is cumbersome to build a physical platform to test all combinations of camera resolutions, locations, orientations, etc., we use a graphics engine (Unity3D) to simulate a room with various avatars animated using motions captured from real subjects with a Kinect v2 sensor. The simulation pipeline is shown in the figure below. First, actions were recorded by Kinect camera, including sequences of skeletal coordinates. Then, a room environment was constructed in Unity 3D graphics engine (see figure above). Finally, the sequences of skeletal coordinates were imported into Unity 3D and various avatars (8 in total – see below) were animated using these coordinates.

The animated avatars were recorded by 5 cameras. The figure below shows a single frame of an avatar captured by 5 cameras while raising arm.
We study the performance impact of spatial resolution from a single pixel up to 10×10 pixels (an extremely low spatial resolution), the impact of temporal resolution from 2 Hz up to 30 Hz and the impact of using up to 5 ceiling cameras.
Results of this study indicate that reliable action recognition for smart-room centric gestures is possible in environments with extremely low spatial and temporal resolutions. An overview of these results is shown in the table below:

Dataset and corresponding project code have been made available here.
![]()
Study 2: Real appearance data from IXMAS dataset
In order to validate our findings on real appearance data, we repeated a subset of our experiments on the multi-view action sequences from the IXMAS action dataset (5 cameras, 10 subjects, 12 actions). We used the static ROIs (64×48 pixels) provided by the dataset, where the subjects occupy most of the field of view, and decimated the spatial and temporal resolutions to simulate extremely low-resolution camera views (see figure below).

We evaluated action recognition performance for spatial resolutions of 16×12, 8×6, 4×3, and 1×1, temporal resolutions of 25 Hz and approximately 2 Hz (each 25 Hz sequence is down-sampled by 12 in time), and camera counts of 5 and 1 (frontal only). CCR was computed in each case using leave-person-out cross validation. The overview of our results is shown in the table below:
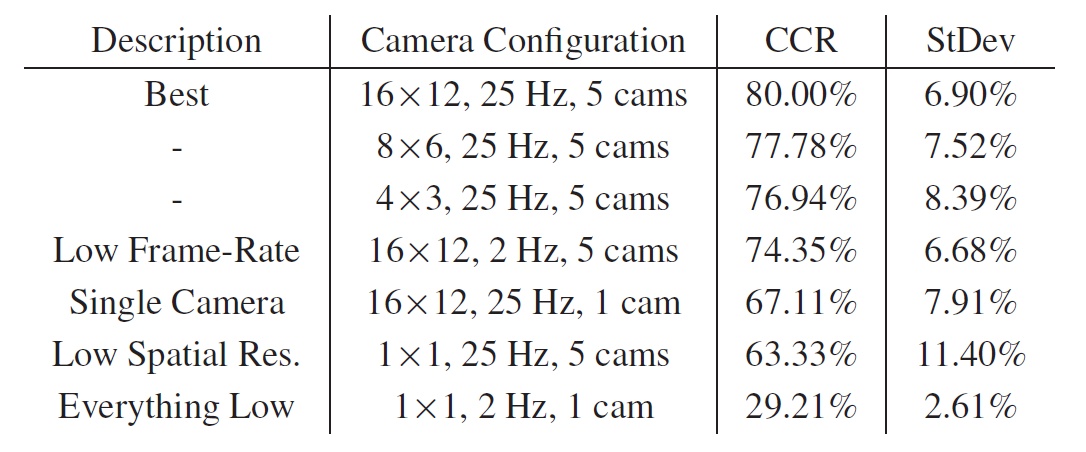
These results on real data are qualitatively consistent with the results on semi-synthetic data: the recognition rates improve with spatial and temporal resolutions and the number of cameras, and the CCR is quite insensitive to the decrease of temporal resolution with around a 5% CCR loss from 25 Hz to 2 Hz. The best-performing configuration has a CCR of 80%. While this is below the best CCR for semi-synthetic data, it is quite comparable. The close qualitative agreement between the results on semi-synthetic and real data is quite encouraging because it validates the simulation-based approach and provides evidence to support the conclusion that a simulation-based study can serve as a fairly reliable proxy for real-world data.
Study 3: Real-time test on a testbed with physical sensors
 We also tested our approach in real time on a testbed with 6 single-pixel sensors (see figure on right). This testbed was built within the Smart Lighting Engineering Research Center at Boston University and Rensselaer Polytechnic Institute. The 6 sensors were networked and the data streams were collected by a Raspberry Pi processor for real-time, nearest-neighbor classification. Two simple actions of raising hands frontally and sideways were performed, and lights of different colors were activated depending on which action was performed. Please see the video below for the demonstration of the performance of the system. As is clear from the video, the two actions can be reliably recognized with only 6 single-pixel sensors and simple classification. These results demonstrate that recognizing human activity in an indoor setting from low resolution data, that does not reveal person’s identity, is feasible.
We also tested our approach in real time on a testbed with 6 single-pixel sensors (see figure on right). This testbed was built within the Smart Lighting Engineering Research Center at Boston University and Rensselaer Polytechnic Institute. The 6 sensors were networked and the data streams were collected by a Raspberry Pi processor for real-time, nearest-neighbor classification. Two simple actions of raising hands frontally and sideways were performed, and lights of different colors were activated depending on which action was performed. Please see the video below for the demonstration of the performance of the system. As is clear from the video, the two actions can be reliably recognized with only 6 single-pixel sensors and simple classification. These results demonstrate that recognizing human activity in an indoor setting from low resolution data, that does not reveal person’s identity, is feasible.
For a more in-depth explanation of our methodology and the aforementioned results please refer to our papers below.
Publications:
- J. Dai, J. Wu, B. Saghafi, J. Konrad, and P. Ishwar, “Towards privacy-preserving activity recognition using extremely low resolution temporal and spatial cameras,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Workshop on Analysis and Modeling of Faces and Gestures (AMFG), pp. 68-76, June 2015.
- J. Dai, B. Saghafi, J. Wu, J. Konrad, and P. Ishwar, “Towards privacy-preserving recognition of human activities,” in Proc. IEEE Int. Conf. Image Processing, pp. 4238-4242, Sept. 2015.