VGAN-Based Image Representation Learning for Privacy-Preserving Facial Expression Recognition
Team: J. Chen, J. Konrad, P. Ishwar
Funding: National Science Foundation (Lighting Enabled Systems and Applications ERC)
Status: Ongoing (2017-2019)
Background:
The recent proliferation of sensors in living spaces is propelling the development of “smart” rooms that can sense and interact with occupants to deliver a number of benefits such as improvements in energy efficiency, health outcomes, and productivity. Automatic facial expression recognition is an important component of human-machine interaction. To date, a wide variety of methods have been proposed to accomplish this, however they typically rely on high-resolution images and ignore the visual privacy of users. Growing privacy concerns will prove to be a major deterrent in the widespread adoption of camera-equipped smart rooms and the attainment of their concomitant benefits. Therefore, reliable and accurate privacy-preserving methodologies for facial expression recognition are needed.
Summary:
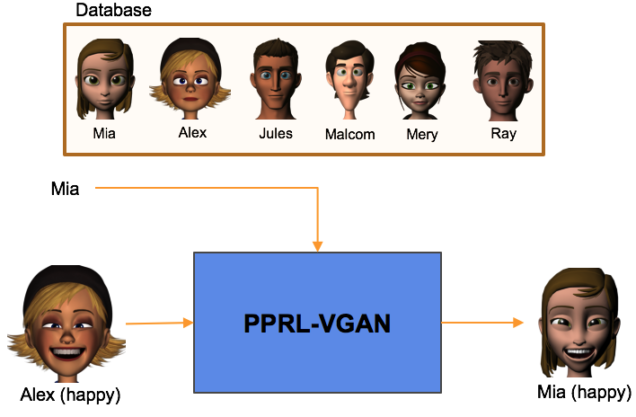
In this work, we leverage the generative power of the Variational Auto-Encoder (VAE) and the generative adversarial network (GAN) to learn an identity-invariant representation of an image while enabling the synthesis of a utility-equivalent, realistic version of this image with a different identity (Fig. 1 ). We call this framework Privacy-Preserving Representation-Learning Variational Generative Adversarial Network (PPRL-VGAN). Beyond its application to privacy-preserving visual analytics, our approach could also be used to generate realistic avatars for animation and gaming.
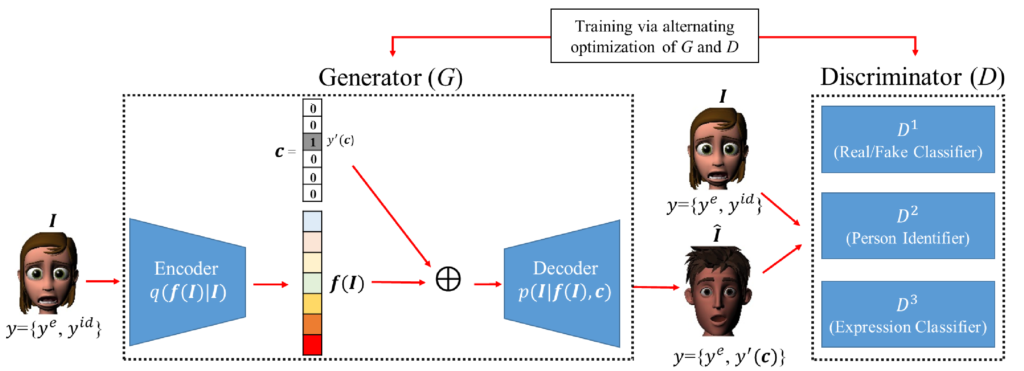
We combine VAEs with GANs by replacing the generator in a conventional GAN, which uses random noise as input, with a VAE encoder-decoder pair, which takes a real image as an input and outputs a synthesized image. As shown in Fig. 1, the encoder learns a mapping from a face image I to a latent representation f(I). The representation is subsequently fed into the decoder to synthesize a face image with some target identity (specified by identity code c) but with the same facial expression as the input image. The discriminator includes multiple classifiers that are trained to (i) distinguish real face images from synthesized ones, (ii) recognize the identity of the person in a face image and (iii) recognize the expression in a face image. During training, feedback signals from the discriminator D guide the generator G to create realistic expression-preserving face images. In addition, as the identity of the synthesized images is determined by the identity code c, the network will learn to disentangle the identity-related information from the latent representation.
Experimental results:
Privacy-preservation vs. data utility:
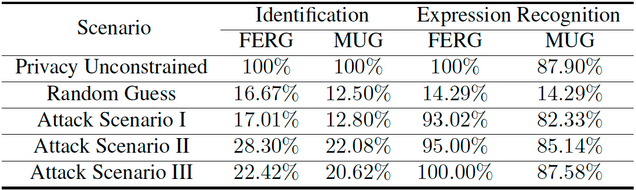
We evaluate privacy-preserving performance of the proposed PPRL-VGAN under three threat scenarios. In the first attack scenario, the attacker has access to the unaltered training set. However, the attacker’s test set consists of all images in the original test set after they have been passed through the trained PPRL-VGAN network. In the second attack scenario, the attacker has access to the privacy-protected training images and knows their underlying ground-truth identities. Therefore, the attacker can train an identifier on training images that have the same type of identity-protecting transformation as the test images. In the third attack scenario, the attacker gets access to the encoder network and can obtain the latent representation for any image.
In terms of utility, we train a dedicated facial expression classifier in each scenario with the available format of training data and the corresponding ground-truth expression labels. Then, we apply this classifier to test data and measure the facial expression recognition performance. Table 1 summarizes the performance of the proposed approach on two facial expression datasets (MUG and FERG) under a privacy-unconstrained scenario (training and testing sets are both unaltered), under a random-guessing attack and under the three attack scenarios described earlier.
Identity replacement/expression transfer:
In addition to producing an identity-invariant image representation, PPRL-VGAN can be applied to an input face image of any identity to synthesize a realistic, expression-equivalent output face image of a target identity specified by the latent code c. This may also be equivalently viewed as “transferring” an expression from one face to another. The following video shows examples of identity replacement for MUG datasets. From top left to bottom right, is an input video followed by synthesized videos with different identity codes. In the video, subjects will show neutral expression and disgust expression periodically. Please note we synthesized the videos frame by frame without modeling the temporal behavior.
Expression morphing:
PPRL-VGAN can be applied to facial expression morphing by doing linear interpolation in latent space. Given a pair of source images I1 and I2 with different expressions of a subject and f(I1), f(I2) their corresponding latent representations. We linearly interpolate f(I1) and f(I2) in the latent space to obtain a series of new representations as follows:
![]() Then, we feed the generated representation and an identity code into the decoder to synthesize a new face image. In Fig. 3, we can see that the facial expression changes gradually with respect to α. These smooth semantic changes indicate the model is able to capture salient expression characteristics in the latent representations.
Then, we feed the generated representation and an identity code into the decoder to synthesize a new face image. In Fig. 3, we can see that the facial expression changes gradually with respect to α. These smooth semantic changes indicate the model is able to capture salient expression characteristics in the latent representations.

Image completion:
PPRL-VGAN can be also applied to an image completion task. Examples of both successful and unsuccessful image completions are shown in Fig. 4. Figure 3a shows examples for which our model was able to accurately estimate the missing image content. This demonstrates that our model learns correlations between different facial features, for example that opening the mouth is likely to appear jointly with raising eyebrows. However, our model occasionally fails (Fig. 3b ). One possible reason for this is that some critical facial features (e.g., lowered eyebrows and narrowed eyes in the angry expression) are missing. A distortion may also occur when a face in the synthesized images is not accurately aligned with the one in the query image.

Implementation Details and Source Code:
- Tensorflow 1.0.1
- Keras 2.0.2
- Model: https://github.com/yushuinanrong/PPRL-VGAN
Tip: if you don’t witness meaningful structures in the synthetic images after 15 epochs, you need to stop training and do it from scratch again.
Publication:
J. Chen, J. Konrad, P. Ishwar, “VGAN-Based Image Representation Learning for Privacy-Preserving Facial Expression Recognition“. In IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), CV-COPS Workshop, 2018.