Multiple viewpoints: More data is better!
Team: J.Wu, P. Ishwar, J. Konrad
Funding: National Science Foundation (CISE-SATC)
Status: Completed(2011-2017)
Summary: This project focuses on discovering the significance of multiple viewpoints in gesture-based authentication. Our goal is to systematically investigate the potential benefits of using data from multiple viewpoints versus a single viewpoint. To achieve this goal, without attempting to “re-invent the wheel”, we simply adopt the current state-of-the-art features and classifiers that have proved successful in the context of recent work on gesture recognition and gesture-based authentication, and focus on the question of the utility of multiple viewpoints. Specifically, we use a popular covariance-based descriptor applied to skeletal joints captured by up to 4 Kinect cameras.

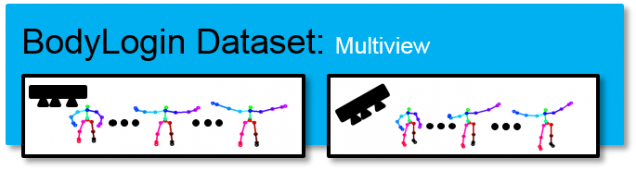
Sample skeletal sequences of a single user gesture captured from three different views using Kinect cameras

Additionally, we offer an insight into performance gains attributable to the use of multiple viewpoints as well as improved robustness in the presence of several real-world degradations (user memory and personal-effects such as backpacks/bags and outerwear) resulting from rigorous tests on a dataset of 40 users. In this dataset, users were asked to perform two gestures. One gesture was a shared gesture (S gesture), and another was a one they selected (user defined gesture). Details of the data (including details on configuration and setup of the Kinects) can be found here.
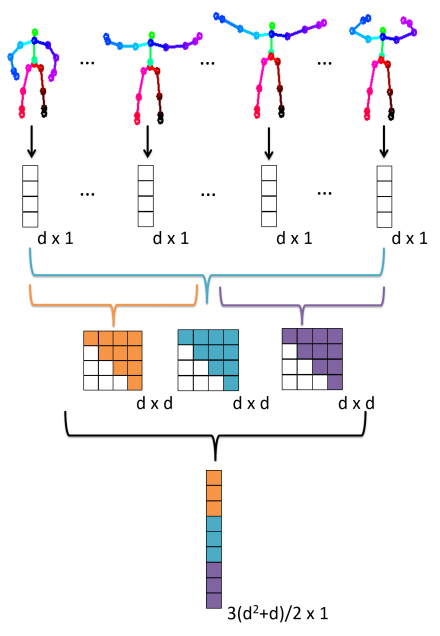
A visualization of the process of constructing a Cov3DJ feature vector from the skeletal sequence of a single view.
The aforementioned procedure only applies to a single Kinect viewpoint. If multiple viewpoints are to be considered some sort of fusion is necessary. In this project we consider two types: score and feature fusion.
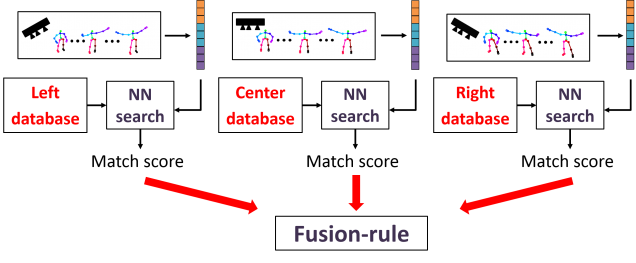
Visualization of score fusion
In score fusion, we consider each Kinect viewpoint to be an independent system. Each system computes a score for a given query gesture against a template from the enrollment database, and an aggregate score across all systems is used to determine an acceptance or rejection. To get a fused score, we apply one of the following operations: min, mean, median.

Visualization of feature fusion
In feature fusion, we consider concatenation: combining features before a covariance matrix is computed. We simply concatenate the feature vectors across all viewpoints.
Results:
We tested the aforementioned features on our acquired dataset under various scenarios. For example, the first row in the tables below shows the Equal Error Rate (EER) percentages when both training and testing data included no degradations. The subsequent rows show results when no degradations were present at training but individual or all degradations were present during testing. The tables below show all results for our 2 considered gestures.

For additional results (other single viewpoints, identification) and more in-depth details on our methodology please refer to our paper below.
To date, we found that two additional viewpoints can provide as much as 26–43\% average relative improvement in the EER for user authentication, and as much as 16–68\% average relative improvement in the Correct Classification Error (CCE) compared to using a single centered Kinect camera. Based on the empirical results presented here, multiple viewpoints undeniably offer clear and significant benefits in terms of both performance and robustness against degradations, over the traditional single-viewpoint setup.
Publications:
- J. Wu, J. Konrad, and P. Ishwar, “The value of multiple viewpoints in gesture-based user authentication,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Workshop on Biometrics, pp. 90-97, June 2014.