Video Condensation by Ribbon Carving
Team: Z. Li, W. Liu, H.-Y. Wu, P. Ishwar, J. KonradFunding: National Science Foundation (CISE-CNS-NOSS)
Status: Completed (2008-2010)
Background: Efficient browsing of long video sequences is a key tool in visual surveillance, e.g., for post-event video forensics, but can also be used for review of motion pictures and home videos. While frame skipping (fixed or adaptive) is straightforward to implement, its performance is quite limited. More efficient techniques have been developed, such as video summarization and video montage but they lose either the temporal or semantic context of events. A recently-proposed method called video synopsis provides even better performance, however, it involves multiple processing stages and is fairly complex.
Summary: In search for an effective and efficient video browsing algorithm, we have been inspired by image seam carving, a method for content-aware still-image re-sizing. In this method, vertical and horizontal seams (connected paths) with lowest cost, e.g., sum of luminance gradient magnitudes along the seam, are removed recursively to meet the target image size. Based on this idea, we developed a novel approach to video synopsis, that we call video condensation. Our approach extends the concept of image seam to video ribbon, a 3-D surface that is rigid either horizontally (vertical ribbon) or vertically (horizontal ribbon). Such a structure of the ribbon permits the use of dynamic programming, originally proposed in seam carving. Furtermore, the ribbon model is flexible and permits an easy adjustment of the compromise between temporal condensation ratio and anachronism of events. Although our approach permits the use of video gradients (3-D) , the most interesting results have been obtained for costs derived from motion labels (moving/static) computed from the video by means of background subtraction. The method is novel in the way information is removed from the space-time video volume, is conceptually simple and relatively easy to implement.
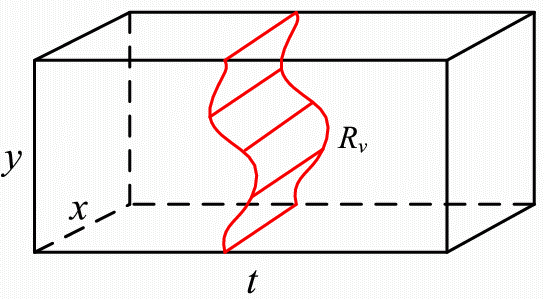 Vertical ribbon
Vertical ribbon
|
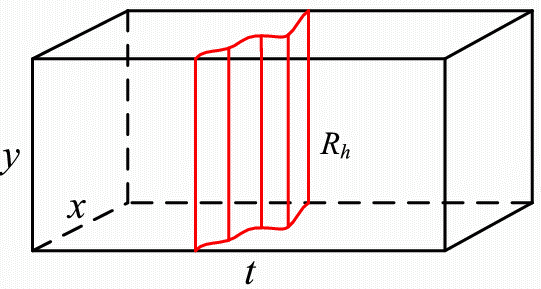 Horizontal ribbon
Horizontal ribbon
|
- magnitude of spatio-temporal luminance gradient (left),
- magnitude of temporal luminance derivative (center),
- activity (motion) labels (right).
| Original video | Condensed video |
|
Highway – original
|
Highway – condensed (8.06:1 ratio)
|
| Overpass – original | Overpass – condensed (2.87:1 ratio) |
| Sidewalk – original | Sidewalk – condensed (2.32:1 ratio) |
Note 2: Occasionally, objects appear to abruptly jump forward or disappear/reappear after a fraction of a second. This is due to frame skipping in the original video (imperfect video capture process), and not an artifact of the condensation algorithm. The effects of frame skipping may be perceptually more prominent in the condensed video because events happen “more quickly” than in the original video but they are present in both.
Note 3: Some condensed frames are void of moving objects but not removed. This is due to the fact that our background subtraction algorithm is imperfect and produces false positives in some frames thus preventing carving.
Publications:
- Z. Li, P. Ishwar, and J. Konrad, “Video condensation by ribbon carving,” Tech. Rep. 2008-03 (Master’s project), Boston University, Dept. of Electr. and Comp. Eng., Sept. 2008.
- W. Liu, “Streaming video condensation by ribbon carving,” Tech. Rep. 2008-07 (Master’s project), Boston University, Dept. of Electr. and Comp. Eng., Dec. 2008.
- Z. Li, P. Ishwar, and J. Konrad, “Video condensation by ribbon carving,” IEEE Trans. Image Process., vol. 18, pp. 2572-2583, Nov. 2009.
- H.-Y. Wu, “Sliding-window ribbon carving for video condensation,” Tech. Rep. 2009-03, Boston University, Dept. of Electr. and Comp. Eng., Dec. 2009.