DeepLogin Dataset
| Motivation | Description | Download Form | Contact |
|---|---|---|---|
Motivation
Depth-sensors, such as the Kinect, have predominately been used as a gesture recognition device. Recent works, however, have proposed to use these sensors for user recognition using biometric modalities such as: face, speech, gait and gesture. The last of these modalities – gestures, used in the context of full-body and hand-based gestures, is relatively new, but has shown promising authentication performance.
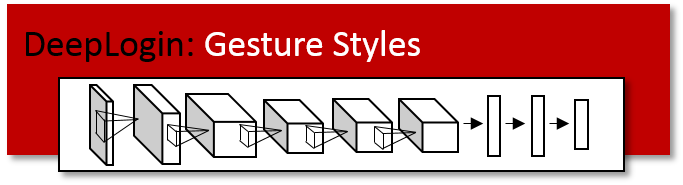
DeepLogin uses two-stream convolutional networks for user recognition. The spatial stream is represented by the usage of depth maps, and the temporal stream is represented by the usage of the optical flow of the depth maps. Both these inputs to the network are provided in this project page.
Description
The DeepLogin dataset has been derived from BodyLogin and HandLogin datasets that we had acquired earlier for other research projects. The extracted data were processed for a direct use in deep convolutional networks. Details of both BodyLogin and HandLogin, as well as what processing has been applied are included below.
BodyLogin consists of 3 sets of depth map sequences, namely BLD-M, BLD-PBD, and BLD-SS, acquired with Kinect v1 cameras. We have combined these 3 datasets into one, thus users overlap. It is a full body multi-view dataset containing gesture sequences of 40 users performing 5 different gestures that are recorded by Kinect v1 sensors. Four of these gestures are predefined: S gesture (user draws an “S” shape with both arms), left-right (user reaches right shoulder with left hand, and then left shoulder with right hand), double-handed arch (user moves both arms in an upwards arch), and balancing (user performs a complex balancing gesture involving arms and legs). The fifth gesture is created by the user (user-defined). Each user performed each gesture about 20 times under varying degradations, such as carrying a bag, wearing a coat, passage of time, and also under spoof attacks. In this project, we train and test with samples across all degradations, and only from the center camera viewpoint, which is the only viewpoint provided.

HandLogin is a dataset containing depth map sequences of in-air hand gestures of 21 users, each performing 4 different gestures that are recorded by a Kinect v2 sensor. These gestures are: compass (move open hand in multiple directions), piano (move fingers as if playing piano), push (move open hand towards and away from the sensor), and flipping fist (twist and curl hand into a fist). Each user performed 10 samples of each gesture.

Both BodyLogin and HandLogin datasets have been processed as follows. Sequences of depth maps from each dataset were post-processed for use with CNNs by centering, cropping/resizing to 224 x 224 pixels and normalizing depth values to the range 0-255 (from the original 16-bit values). In addition, optical flow was computed from consecutive pairs of depth images using the algorithm described here and then stored in PNG files as two 8-bit color components (horizontal and vertical coordinates; the third color component is assigned a fixed value of zero) after suitable scaling and quantization. Both depth frames and optical flow fields are provided at a spatial resolution of 224 x 224 pixels for direct use in single-stream or two-stream CNNs. Note that no code is provided to recover the original high-resolution optical-flow components from the scaled and quantized 8-bit values stored in the PNG files. The original optical-flow vectors are not needed in CNN training and testing as long as the data used in both stages has the same format; it is the relationship (correlation) between depth values and optical-flow vectors that is important, not the actual values themselves.
We have also included many of our fine-tuned Caffe model files (.caffemodel and deploy .prototxt) for user identification and authentication for both of these datasets.
For additional information on Caffe and MatCaffe see: here and here. For more in-depth individual information about these datasets, please see their original dataset pages: HandLogin and BodyLogin. For additional information (such as training parameters, the study, etc.) about the project please refer to the paper listed below.
Download Form
You may use this dataset for non-commercial purposes. If you publish any work reporting results using this dataset, please cite the following paper:
- J. Wu, P. Ishwar, and J. Konrad, “Two-Stream CNNs for Gesture-Based Verification and Identification: Learning User Style,” to appear in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Workshop on Biometrics, June 2016.
To access the download page, please complete the following form.
When ALL the fields have been filled, a submit button will appear which will redirect you to the download page.
Contact
Please contact [jonwu] at [bu] dot [edu] if you have any questions.
Acknowledgements
The development of this dataset was supported by the NSF under award CNS-1228869 and by Co-op Agreement No. EEC-0812056 from the ERCP, and by BU UROP.
We would also like to thank the students of Boston University for their participation in the recording of our dataset.