Unity Activity Dataset: Low Resolution for Privacy
{kind=link}
{kind=link}
{kind=link}
| Description | Data Acquisition | Data Definitions | Download Form | Contact |
|---|---|---|---|---|
Description
With activity recognition slowly entering mainstream application areas such as smart conference and living rooms, concerns about privacy is quickly growing. In order to study trade-offs between activity recognition performance and degraded spatio-temporal data resolutions (surrogate for privacy preservation), we developed a novel Unity Activity Dataset. In this dataset, the Unity3D© graphics engine is used to animate various avatars based on the motions of real-subjects captured by a Kinect v2 camera. Then, grayscale videos are captured at various spatio-temporal resolution from several cameras arranged around a simulated room where the avatar’s activity takes place.
Data Acquisition
The pipeline of data acquisition is illustrated in the figure below. Motions from real users were first captured using a Kinect v2 depth sensor. Skeletal information was then extracted using Kinect Skeleton Pose Estimator. A seminar room was simulated inside Unity3D©. Real motions were then used to animate avatars in the simulated room. Five virtual cameras inside the room recorded the actions and exported grayscale videos. Details are elaborated below.
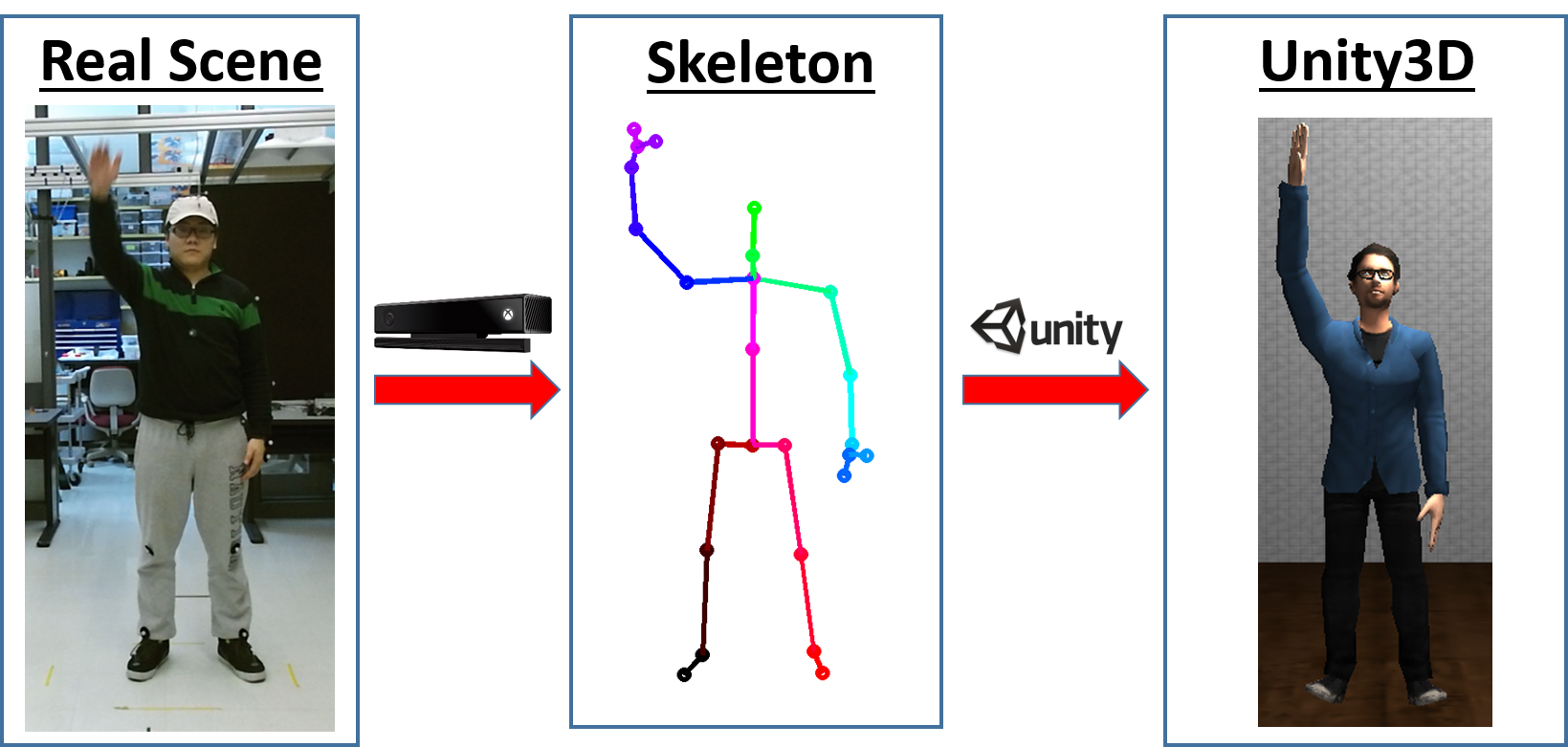
Phase 1: Capture of real motions
A total of 12 college-affiliated users (7 men and 5 women, mostly college-aged) helped during the recording of real human activities. Each user was asked to perform 9 actions typical of seminar-room activities. These actions are:
- Answering Mobile (removing mobile from a pocket, unlocking it and raising it to ear level; ~ 6-17 seconds)
- Checking Mobile (removing mobile from a pocket, unlocking it and manipulating the device to read email, surf the web, etc.; ~ 10-17 seconds)
- Raising Volume (raising right hand up with the palm facing up as if requesting to increase the sound volume; ~ 2-5 seconds)
- Lowering Hands (quickly raising both hands up in tandem and then slowly lowering them in tandem as if requesting an audience to settle down; ~ 3-9 seconds)
- Raising Hand (raising right hand straight up as if voting or asking a question; ~ 3-7 seconds)
- Writing on Board (~ 4-12 seconds)
- Clapping (~ 4-10 seconds)
- Walking (~ 3-5 seconds)
- Sitting (~ 6-11 seconds)
Each user repeated each action 3 times. All action samples were performed while standing at a rest position (hands at the side) in front of a single forward-facing Kinect v2 depth camera. Further, for each repetition users were requested to leave and re-enter the field of view of the camera so as to reduce position and pose biases between samples.
Phase 2: Extraction of skeletal information
Skeletal information was extracted from the recorded real-human motion using Kinect Skeleton Pose Estimator SDK.
Phase 3: Simulation of a seminar room in Unity3D©
A room was then built in Unity3D©. The room was a square-shaped seminar room. One omnidirectional light source was placed above the room for lighting. In this data-set, the room is equipped with 5 grayscale cameras. These cameras are placed at the vertices of a pentagon, looking at the center of the room. Cameras are configured with same size of field-of-view (lens, zoom, etc.).

Phase 4: Animation and recording.
As shown below, 8 avatars (5 males and 3 females) were used in this data-set. These avatars are provided by Mixamo©
Real-motion data was mapped onto avatars with same gender for animation. All possible mapping combination were created: 7(male users) x 5(male avatars) + 5(female users) x 3(female avatars) = 50(combinations).
We generated data at 6 different spatial resolutions: 1 x 1, 2 x 2, 3 x 3, 4 x 4, 5 x 5, and 10 x 10 pixels, all at 30 Hz temporal resolution.
Data Definitions
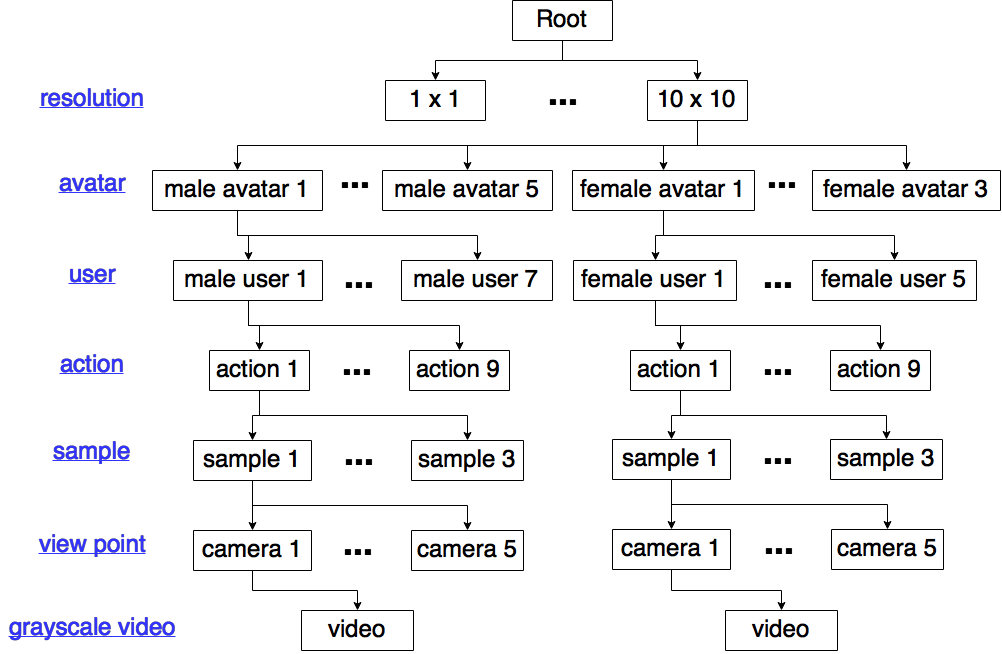
The dataset is organized in the form of the following tree structure and stored as a multi dimensional cell array:
- level 1 nodes are different resolutions.
- level 2 nodes are avatars used for animation
- level 3 nodes are users whose motion data is mapped onto that avatar (the parent node); each of theses users and the corresponding avatar are of the same gender.
- level 4 nodes are actions, level 5 nodes are different samples and level 6 nodes are different camera views.
- leaf nodes are the grayscale sequences.
Download Form
You may use this dataset for non-commercial purposes. If you publish any work reporting results using this dataset, please cite the following paper:
J. Dai, J. Wu, B. Saghafi, J. Konrad, and P. Ishwar, “Towards Privacy-Preserving Activity Recognition Using Extremely Low Temporal and Spatial Resolution Cameras,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Workshop on Analysis and Modeling of Faces and Gestures (AMFG), June. 2015.
To access the download page, please complete the following form. When ALL the fields have been filled, a submit button will appear which will redirect you to the download page.
Contact
Please contact [jidai] at [bu] dot [edu] if you have any questions.
Acknowledgements
This dataset was supported primarily by the Engineering Research Centers Program of the National Science Foundation under NSF Cooperative Agreement No. EEC-0812056.
We would like to thank the students of Boston University for their participation in the recording of our dataset.