Silhouettes versus Skeletons: Can less data be as good yet more robust?
Team: J.Wu, K. Lai, P. Ishwar, J. Konrad
Funding: National Science Foundation (CISE-SATC)
Status: Completed (2011-2017)
Summary: This project focuses on two issues in gesture-based authentication. First, which data produced by a Kinect camera performs better in gesture-based authentication: silhouettes or skeletons? A person’s silhouette can be easily derived from a depth map produced by Kinect camera (see the picture above). However, due to illumination, clothing, occlusions, etc., silhouettes may be locally erroneous and may potentially increase authentication errors. Alternatively, a person’s skeleton produced by Kinect SDK can serve as the input to an authentication algorithm. Skeletons produced by Kinect SDK are quite robust to illumination, clothing and occlusions, but contain fewer bits of information than silhouettes. The second issue we tackle is the impact of some real-world degradations, such as user memory of gestures, and of various personal-effects, such as backpacks and heavy clothing, on the performance of gesture-based authentication. We provide a careful experimental study of our algorithms considering both of these issues.

In order to achieve these goals, we acquired gesture data from 40 users. Gestures with various degradations, namely user-memory and personal effects (heavy coats, bags, etc.), were recorded. Users were asked to perform two gestures. One gesture was a shared gesture (S gesture), and another was a gesture selected by the users on their own (user-defined gesture). Details of the acquired data can be found here.
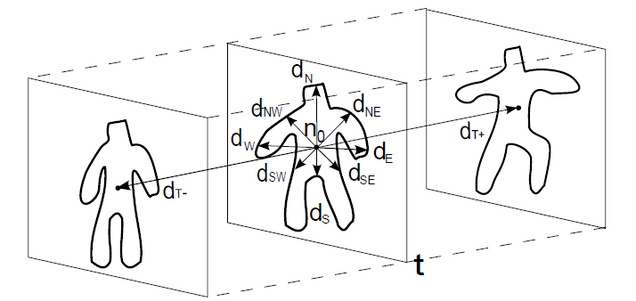
To generate skeletal features, skeletal pose-estimates (x-y-z coordinates — see figure below) were extracted from the Kinect v1 Windows SDK. Three distances between skeletal features of a query user and enrolled users were considered. The first two distances mirrored the kind applied to silhouette features above; empirical covariance matrices were formed from per-frame skeletal pose-estimates, and nearest-neighbor Euclidean or log-Euclidean distances between matrices were considered. The last distance was derived from dynamic time warping (DTW), which computes a non-linear alignment distance between two skeletal sequences.

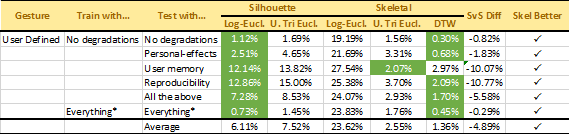
Results: The aforementioned features were both evaluated on our acquired dataset. We tested the performance of both silhouette and skeleton features under various scenarios. For example, the first row in the tables below shows the results when both training and testing data included no degradations. The subsequent rows show results when no degradations were present at training but individual or all degradations were present during testing. The tables below show all results for our 2 considered gestures.

For additional results (identification and group level authentication) and more in-depth details on our methodology, please refer to the papers below and, in particular to the AVSS-2014 paper [4].
To date, we obtained overall Equal Error Rates (EER — equal false rejection and false acceptance rates) showing that skeletal features outperform silhouette features on average by 4.89%. Although our conclusions about the improved performance with skeletal features cannot be drawn in every scenario, our results indicate that skeletal features are always preferable when training data lacks degradations that are present during testing. Thus, in situations where large quantities of varied training data cannot be obtained, skeletal features may be preferable.
Publications:
- K. Lai, J. Konrad, and P. Ishwar, “Towards gesture-based user authentication,” in Proc. IEEE Int. Conf. Advanced Video and Signal-Based Surveillance (AVSS), Sep. 2012, pp. 282-287.
- J. Wu, J. Konrad, and P. Ishwar “Dynamic Time Warping for Gesture-Based User Identification and Authentication with Kinect”, in Proc. IEEE Int. Conf. on Acoustics, Speech and Signal Proc. (ICASSP), May 2013, pp. 2371-2375.
- Article in BU Today: http://www.bu.edu/today/2013/opening-movements
- J. Wu, P. Ishwar, and J. Konrad, “Silhouettes versus skeletons in gesture-based authentication with Kinect,” in Proc. IEEE Int. Conf. Advanced Video and Signal-Based Surveillance (AVSS), pp. 99-106, Aug. 2014.