Background Subtraction for Unseen Videos (BSUV-Net)
Team: M.O. Tezcan, P. Ishwar, J. Konrad
Funding: Advanced Research Projects Agency – Energy (ARPA-E), Department of Energy
Status: Ongoing (2019-)
Background: Background subtraction is a basic task in computer vision and video processing often applied as a pre-processing step for object tracking, people detection, activity recognition, etc. Recently, a number of successful background-subtraction algorithms have been proposed, however, nearly all of the top-performing ones are supervised. Moreover, most of these approaches are scene-optimized, i.e., their success relies upon the availability of some annotated frames of the test videos during training. Consequently, their performance on completely “unseen” videos is undocumented in the literature. In this work, we propose a new, supervised, background-subtraction algorithm for unseen videos (BSUV-net) based on a fully-convolutional neural network.
Summary: BSUV-Net is a fully-convolutional neural network for predicting foreground of an unseen video. A key feature of this approach is that the training and test sets are composed of frames originating from different videos. This guarantees that no ground-truth data from the test videos have been shown to the network in the training phase. By employing two reference backgrounds at different time scales, BSUV-Net addresses two challenges often encountered in BGS: varying scene illumination and intermittently-static objects that tend to get absorbed into the background. We also propose a novel data augmentation method that further improves BSUV-Net’s performance under varying illumination. Furthermore, motivated by recent work on the use of semantic segmentation in BGS, we improve our method’s accuracy by augmenting the reference-background and current-frame inputs with corresponding semantic information.
Scene-Optimized Training: Different frames from the same videos used in training and tesing.
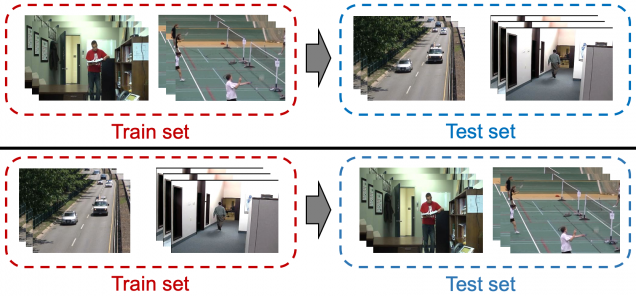
Scene-Agnostic Training using Cross-Validation: Frames from different videos used in training and testing
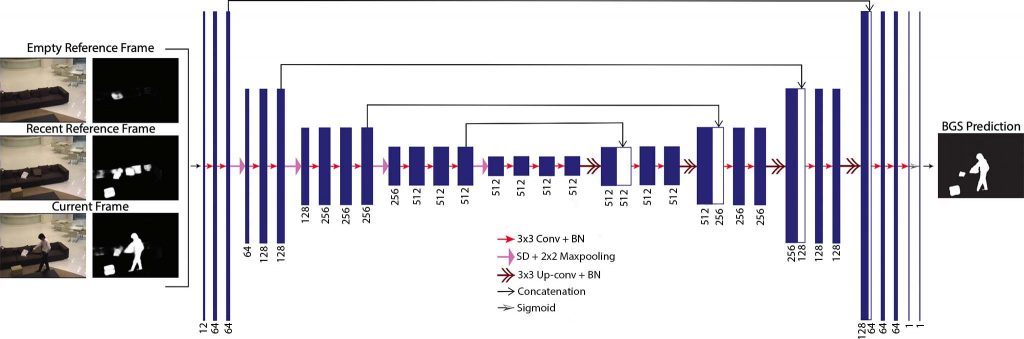
Technical Approach: Segmenting an unseen video frame into foreground and background regions without using any information about the background would be an ill-defined problem. In BSUV-Net, we use two reference frames to characterize the background. One frame is an empty background frame, with no people or other objects of interest, which can be identified manually (e.g., at camera installation), captured using side information (e.g., door sensor in indoor scenarios) or computed (e.g., median filtering over a long time span, such as hours or days). This provides an accurate reference that is very helpful for detecting intermittently-static objects as the foreground (e.g., a car stopped at traffic lights). However, due to dynamic factors, such as illumination variations, this reference frame may not be valid after some time. To counteract this, we use another reference frame that characterizes recent background, for example by computing the median of 100 frames immediately preceding the frame being processed. However, this frame might not as accurately represent the background as the first reference frame since we cannot guarantee that there will be no foreground objects in it (if such objects are present for less than 50 frames, the temporal median will suppress them). By using two reference frames captured at different time scales, we aim to leverage benefits of each frame type.
In addition to RGB images, we also use semantic information of each input frame as additional input channels to our neural network. To extract semantic information, we use a state-of-the-art CNN called DeepLabv3 trained on ADE20K. We categorize the classes used in ADE20K as either foreground or background classes, and compute Foreground Probability Maps (FPMs) of the input frames as follows. Each pixel of FPM represents the probability of that pixel belonging to a foreground object. We compute FPM for all three inputs (empty and recent backgrounds and also the current frame). As a result, the input of BSUV-Net has 12 channels (RGB + FPM for each input) as shown below.
Experimental Results: In order to evaluate the performance of BSUV-Net, we used CDNet-2014, the largest BGS dataset with 53 natural videos from 11 categories including challenging scenarios such as shadows, night videos, dynamic background, etc.
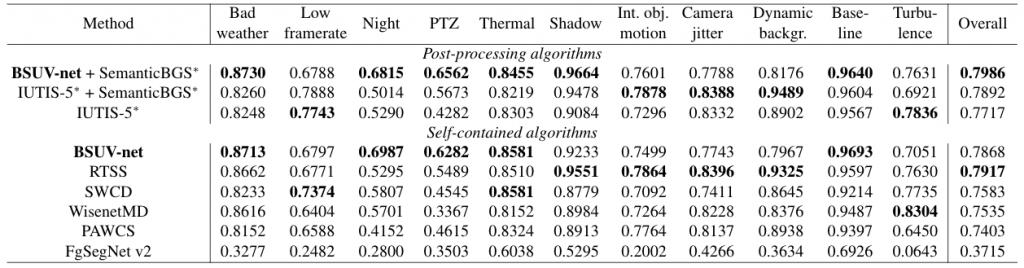
The table below compares BSUV-Net against state-of-the-art background subtraction algorithms in terms of seven different metrics. Since BSUV-Net is scene-agnostic, comparing it with scene-optimized algorithms would not be fair. Instead, we compare BSUV-Net with state-of-the-art unsupervised algorithms which, by definition, are scene-agnostic. We group these algorithms under self-contained algorithms category. We also include the results of IUTIS-5 and SemanticBGS, but we list them separately because these are post-processing algorithms (denoted by * symbol in the table below). Note, that both IUTIS-5 and SemanticBGS can be applied to any background subtraction algorithm, including BSUV-Net, to improve its performance. To show this, we report the output of BSUV-Net post-processed by SemanticBGS. We also include the scene-agnostic performance of FgSegNet v2 since its scene-optimized version is one of the best performing algorithms on CDNet-2014.
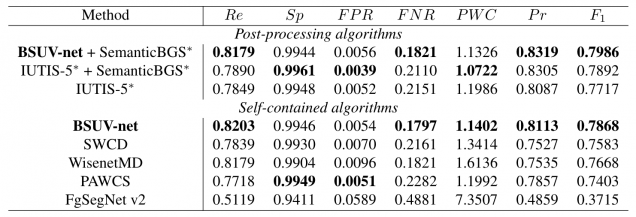
Clearly, BSUV-Net outperforms its competitors on almost all of the metrics. The F-score performance demonstrates that BSUV-Net achieves excellent results without compromising either Recall or Precision. The table above also shows that the performance of BSUV-Net can be improved even further by combining it with SemanticBGS. The combined algorithm outperforms all of the scene-agnostic algorithms that are available at changedetection.net.
The table below compares the per-category F-Score performance of BSUV-Net against state-of-the-art background subtraction algorithms. Individual columns report the F-Score for each of the 11 categories from changedetection.net, while the last column reports the mean F-Score across all categories. It can be observed that BSUV-Net achieves the best performance in 5 out of 11 categories, but it is outperformed by RTSS in terms of the overall performance. BSUV-Net performs significantly poorer than RTSS and some other algorithms in “intermittent object motion”, “camera jitter”, “dynamic background” and “turbulence” categories. We believe this is related to the supervised nature of BSUV-Net. Since it is a data-based algorithm and the representation of these categories in CDNet-2014 is limited, BSUV-Net is not able to capture the necessary details to solve these challenges. BSUV-Net has a striking performance advantage in the “night” category. All videos in this category are traffic-related and many cars have headlights turned on at night which causes significant local illumination variations in time. BSUV-Net’s excellent performance in this category demonstrates that the proposed model is indeed largely illumination-invariant.
A visual comparison of BSUV-Net with SWCD and WisenetMD is shown below. Each row shows a sample frame from one of the videos in one of the 9 categories. It can be observed that BSUV-Net produces visually the best results for almost all categories.

In the “night” category, SWCD and WisenetMD produce many false positives because of local illumination changes. BSUV-Net produces better results since it is designed to be illumination-invariant. In the “shadow” category, BSUV-Net performs much better in the shadow regions. Results in the “intermittent object motion” and “baseline” categories show that BSUV-Net can successfully detect intermittently-static objects. It is safe to say that BSUV-Net is capable of simultaneously handling the discovery of intermittently-static objects and also the dynamic factors such as illumination changes.
An inspection of results in the “dynamic background” category shows that BSUV-Net has detected most of the foreground pixels but failed to detect the background pixels around the foreground objects. We believe this is due to the blurring effect of the median operation that we used in the computation of background frames. Using more advanced background models as an input to BSUV-Net might improve the performance in this category.
More details about BSUV-Net and a detailed ablation study can be found in our paper referenced below.
Source Code: The inference code of BSUV-Net is publicly available at github.com/ozantezcan/BSUV-Net-inference.
Publications:
- M.O. Tezcan. P. Ishwar, and J. Konrad, “BSUV-Net: A fully-convolutional neural network for background subtraction of unseen videos”, in Proc. IEEE/CVF Winter Conf. on Applications of Computer Vision (WACV), 2020.