Privacy-Preserving Action Recognition using Deep Convolutional Neural Networks
Team: Jiawei Chen, Jonathan Wu, Janusz Konrad, Prakash Ishwar
Funding: National Science Foundation (Lighting Enabled Systems and Applications ERC)
Status: Ongoing (2016-…)
Background: Human action and gesture recognition has received significant attention in the computer vision and signal processing communities. Recently, various ConvNet models have been applied in this context and achieved substantial performance gains over traditional methods that are based on hand-crafted features. As promising as ConvNet-based models are, they typically rely upon data at about 200 x 200-pixel resolution that is likely to reveal an individual’s identity. However, as more and more sensors are being deployed in our homes and offices, the concern for privacy only grows. Clearly, reliable methods for human activity analysis at privacy-preserving resolutions are urgently needed.
Summary: We leveraged deep learning techniques and proposed multiple, end-to-end ConvNets for action recognition from extremely Low Resolution (eLR) videos (e.g., 16 × 12 pixels). We proposed multiple eLR ConvNet architectures, each leveraging and fusing spatial and temporal information. Further, in order to leverage high resolution (HR) videos in training, we incorporated eLR-HR coupling to learn an intelligent mapping between the eLR and HR feature spaces. The effectiveness of this architecture has been validated on two public datasets on which our algorithms have outperformed state-of-the-art methods.
Technical Approach:
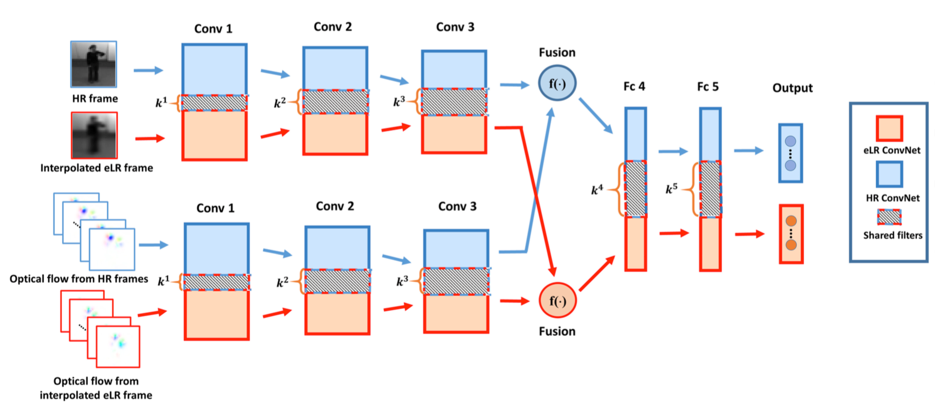
Fusion of the two-stream networks: Multiple works have extended two-stream ConvNets by combining the spatial and temporal cues such that only a single, combined network is trained. This is most frequently done by fusing the outputs of the spatial and temporal network’s convolutional layers with the purpose of learning a correspondence of activations at the same pixel location. In this project, we explored and implemented three fusion methods (concatenation, summation, convolution) in the context of eLR videos.
Semi-coupled networks: Applying recognition directly to eLR video is not robust as visual features tend to carry little information at such low resolutions. However, it is possible to augment ConvNet training with an auxiliary, HR version of the eLR video, while only using an eLR video during testing. In this context, we proposed semi-coupled networks which share filters between eLR and HR fused, two-stream ConvNets. The eLR two-stream ConvNet takes an eLR RGB frame and its corresponding eLR optical flow frames as input. The HR two-stream ConvNet simply takes HR RGB and its corresponding HR optical flow frames as input. In layer number n of the network (n = 1, . . . , 5), the eLR and HR two-stream ConvNets share k(n) filters. During training, we leverage both eLR and HR information, and update the filter weights of both networks in tandem. During testing, we decouple these two networks and only use the eLR network which includes the shared weights.
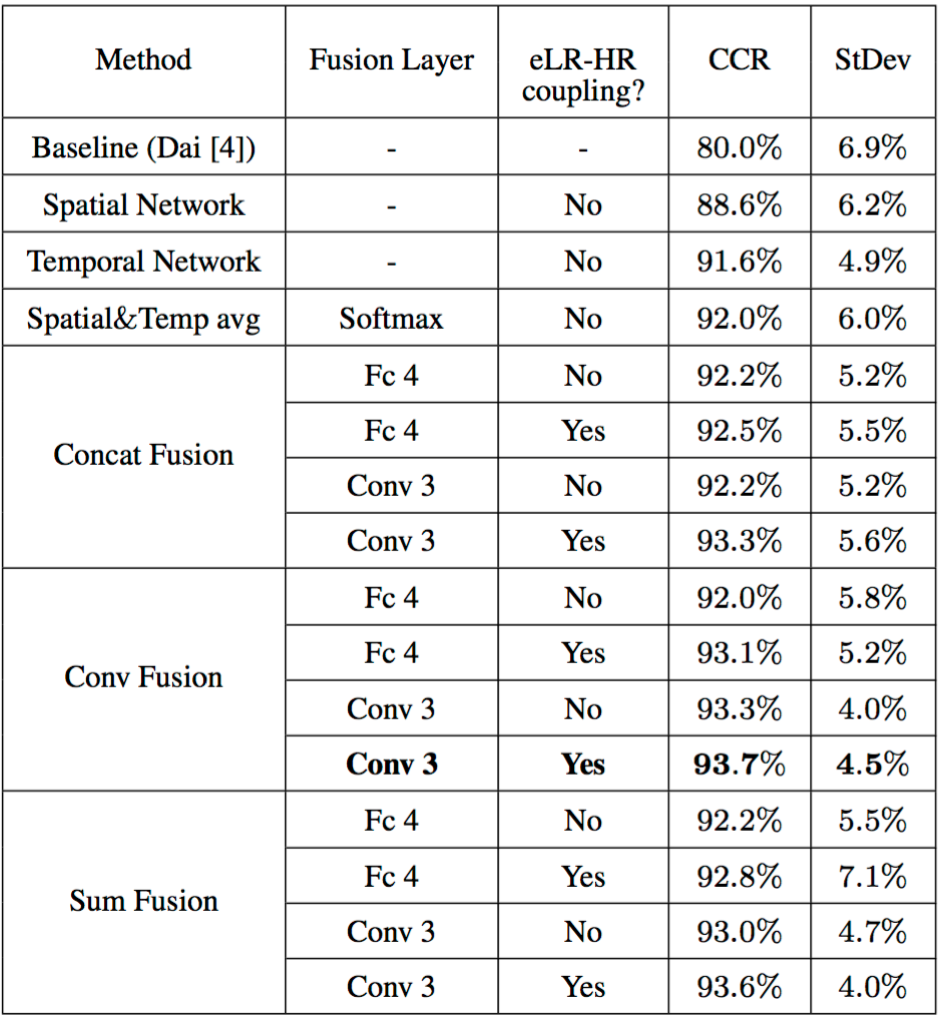
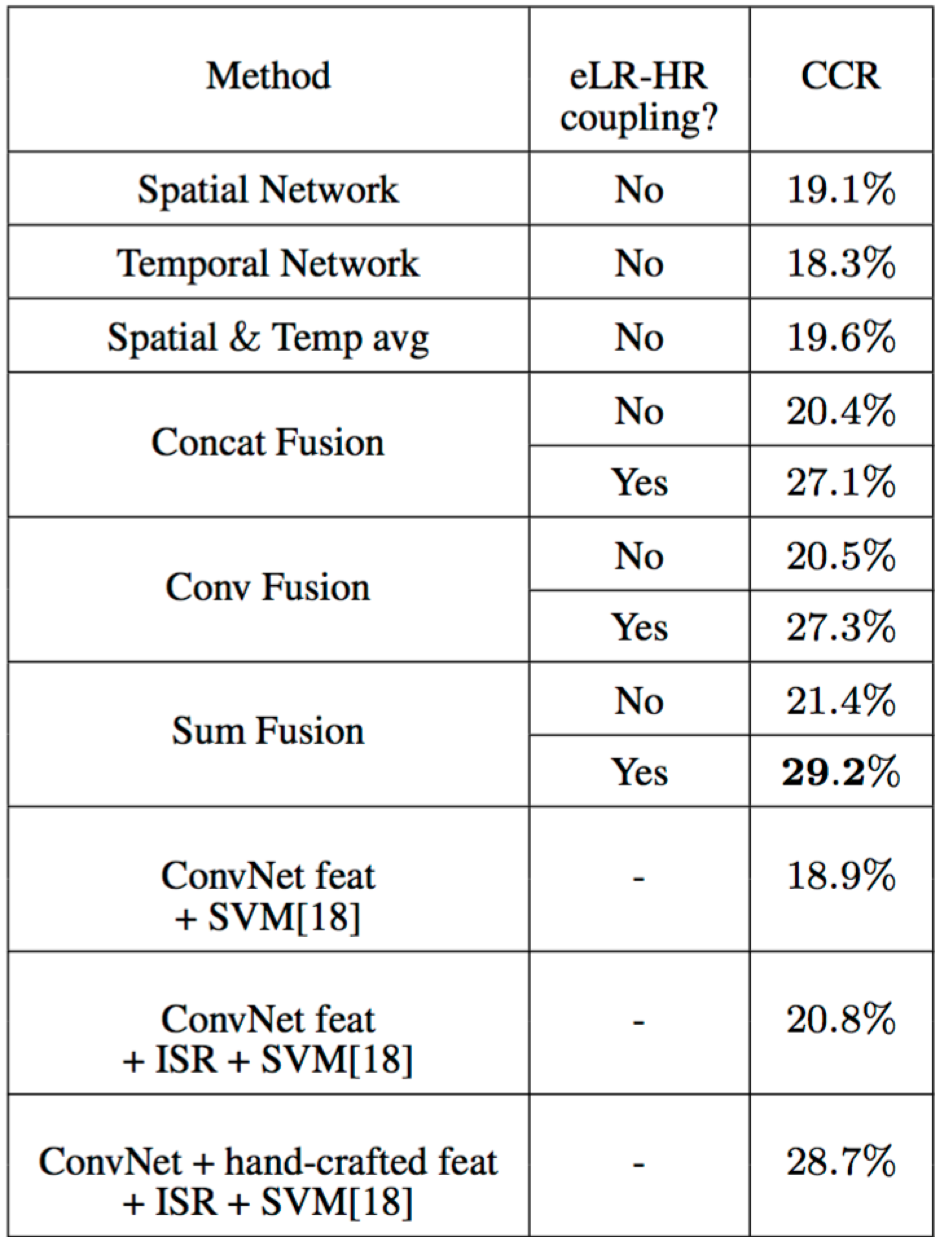
Experimental Results: In order to confirm the effectiveness of our proposed method, we conducted experiments on two publicly-available video datasets. The results below demonstrate that we outperform state-of-the-art methods on both datasets.
Source Code (with ConvNet models): https://github.com/yushuinanrong/Semi-Coupled-Two-Stream-Fusion-ConvNets-for-Action-Recognition-at-Extremely-Low-Resolution
Publications:
- J. Chen, J. Wu, J. Konrad, and P. Ishwar, “Semi-Coupled Two-Stream Fusion ConvNets for Action Recognition at Extremely Low Resolutions,” in Proc. 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Mar. 2017.