BSUV-Net 2.0
Team: M.O. Tezcan, P. Ishwar, J. Konrad
Funding: Advanced Research Projects Agency – Energy (ARPA-E), Department of Energy
Status: Ongoing (2019-)
Background: Recently, we introduced BSUV-Net, a novel supervised background-subtraction algorithm designed for unseen videos that showed superior performance compared to its competitors. One of the key elements behind the success of BSUV-Net was its use of temporal data augmentation to mimic illumination variations that might happen in real-world applications. In BSUV-Net 2.0, we extend this idea and introduce several spatio-temporal data augmentations designed to mimic some challenging scenarios and further increase the robustness of BSUV-Net. We also introduce a real-time version of BSUV-Net 2.0 which also outperforms state-of-the-art methods.
Summary: In this work, we introduce a comprehensive suite of spatio-temporal data augmentation methods, and adapt them to BSUV-Net. The proposed augmentations address some key BGS challenges, such as PTZ (pan-tilt-zoom) operation, camera jitter and presence of intermittently-static objects. We conduct video-agnostic performance analysis and show that these data augmentations significantly increase algorithm’s performance for targeted categories without any significant loss of performance in other categories. We name our improved algorithm BSUV-Net 2.0 and show that it significantly outperforms state-of-the-art background-subtraction algorithms on unseen videos. We also introduce a real-time version of BSUV-Net 2.0 and call it Fast BSUV-Net 2.0. Finally, we propose a 4-fold cross-validation strategy to facilitate fair and streamlined comparison of unsupervised algorithms with video-agnostic supervised algorithms, which should prove useful for future background-subtraction algorithm comparisons on CDNet-2014.
Spatio-Temporal Data Augmentations: BSUV-Net 2.0 uses a set of spatio-temporal data augmentations to attack the most common challenges in BGS. The figure below shows examples of these data augmentations. The first row (a) shows the original input and the subsequent rows show sample results of the following augmentations: (b) spatially-aligned crop (SAC), (c) randomly-shifted crop (RSC), (d) PTZ camera crop, (e) illumination difference (ID), (f) intermittent-object addition (IOA).

Video-Agnostic Evaluation Strategy on CDNet-2014 for Supervised Algorithms: CDNet-2014 is a comprehensive dataset that provides some ground-truth frames from all of its videos to the public, but keeps others internally for algorithm evaluation. Since it does not include any videos without labeled frames, it is not directly suitable for testing of video-agnostic supervised algorithms. Here, we introduce a simple and intuitive 4-fold cross-validation strategy for CDNet-2014. We grouped all videos in the dataset and each category into 4 folds (see the table below) as evenly as possible.
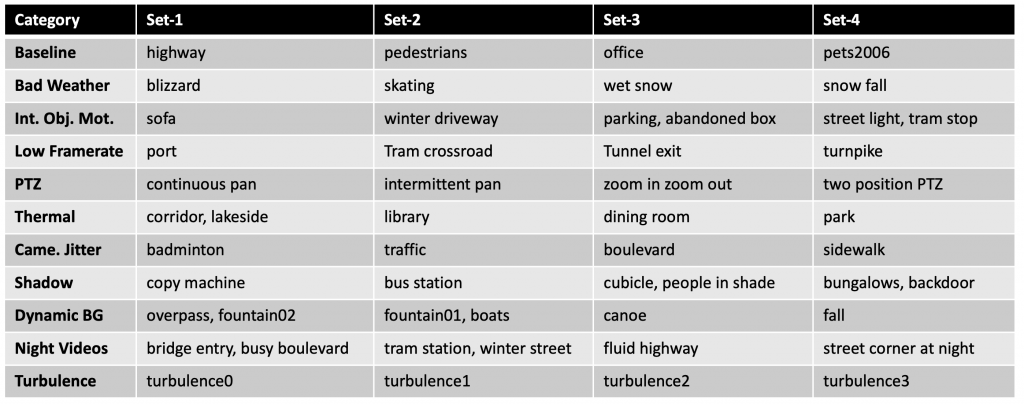
The proposed video-agnostic evaluation strategy is to train any supervised background-subtraction algorithm on three of the folds and test on the remaining fold, and replicate the same process for all 4 combinations. This approach will provide results on the full CDNet-2014 dataset which can be uploaded to the evaluation server to compare against state of the art. We believe this cross-validation strategy will be very beneficial for the evaluation of future background subtraction algorithms.
Experimental Results: We assess the impact of each spatio-temporal data augmentation method that we introduced. As the baseline network, we use BSUV-Net with only spatially-aligned crop (SAC) augmentation and random Gaussian noise. The table below shows F-score for each category of CDNet-2014 for frames with publicly-available ground truth.

It can be observed that each augmentation type significantly improves the performance on related categories (randomly shifted crop – on “Camera jitter”, PTZ camera crop – on “PTZ”, illumination difference – on “Shadow”, intermittent object addition – on “Intermittent object motion”), but combining all augmentations decreases the performance significantly on some categories (e.g., night and intermittent object motion). We believe this is due to trade-offs between the effects of different augmentations. For example, when a static background object starts moving it should be labeled as foreground, but a network trained with a randomly-shifted crop augmentation can confuse this input with an input from the “Camera jitter” category and continue labeling the object as background. Still, the overall performance of BSUV-Net 2.0 that uses all augmentations handily outperforms the overall performance for individual augmentations.
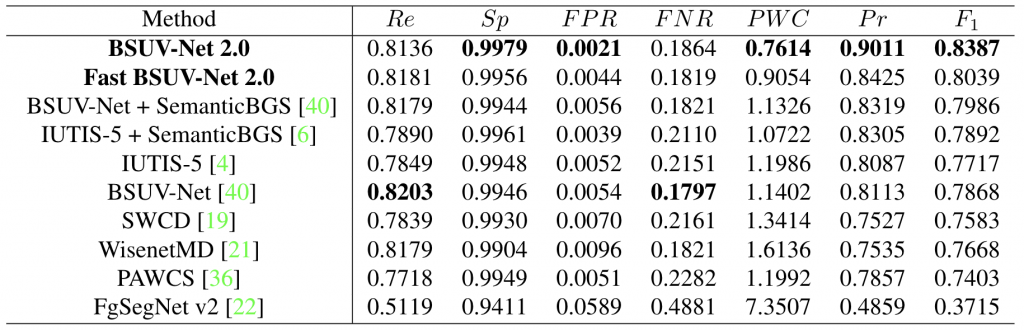
We also introduce a real-time version of BSUV-Net 2.0 called Fast BSUV-Net 2.0. Fast BSUV-Net 2.0 has almost the same architecture as BSUV-Net 2.0, except it does not use the FPM channel to be able to achieve real-time inference. The table below shows a speed and performance comparison of the two versions. The speed has been evaluated using am Nvidia Tesla P100 GPU.

Clearly, while Fast BSUV-Net 2.0 has lower performance, it can be used in real-time applications at 320 x 240 spatial resolution, which is very similar to the resolution used in training. For higher-resolution videos, one can easily feed decimated frames into Fast BSUV-Net 2.0 and interpolate the resulting BGS predictions to the original resolution.
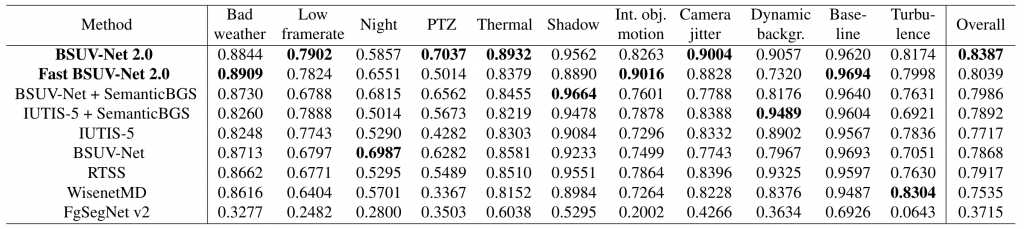
Using CDNet-2014, we compare the performance of BSUV-Net 2.0 and Fast BSUV-Net 2.0 with state-of-the-art background-subtraction algorithms that are designed for and tested on unseen videos (see the table below). We did not include the results of scene-optimized algorithms since it is not fair to compare them against video-agnostic algorithms.
BSUV-Net 2.0 outperforms all state-of-the-art algorithms by at least ~5% in terms of the F-score. Fast BSUV-Net 2.0 also outperforms all state-of-the-art algorithms while being ~5 times faster than BSUV-Net 2.0 during inference. The table below shows the comparison of F-Score results for each category. In 7 out of 11 categories, either BSUV-Net 2.0 or Fast BSUV-Net 2.0 achieve the best performance, including most of the categories that we designed the augmentations for (an exception is the “Night” category). However, note that the best-performing algorithm in the “Night” category is BSUV-Net which uses only the illumination-difference augmentation. Thus, it focuses on videos with illumination differences such as night videos.
The figure below qualitatively compares the performance of BSUV-Net 2.0 with state-of-the-art video-agnostic background-subtraction algorithms on a several videos from CDNet-2014. Clearly, BSUV-Net 2.0 produces the best visual results in a variety of scenarios. Results for “Camera jitter” and “PTZ” categories show the effectiveness of BSUV-Net 2.0 in removing false positives resulting from camera motion. In the example from “Intermittent object motion” category, the car on the left is starting to back-up from the driveway and most of the algorithms produce false positives at the location where the car had been parked, whereas BSUV-Net 2.0 successfully eliminates these false positives. Results for “Dynamic background” show that BSUV-Net 2.0 is very effective in accurately delineating the boundary between foreground objects and the background.

BSUV-Net 2.0 In-the-Wild: In order to demonstrate the generalization capacity of BSUV-Net 2.0, we also tested it on live video of a street crossing in Tokyo, Japan recorded from www.youtube.com/watch?v=RQA5RcIZlAM. The videos below show the output of BSUV-Net 2.0 when applied to two video clips recorded at different times. In both videos, the original recording is shown on the left, foreground/background prediction is shown in the middle and their combination (darker pixels represent background regions and brighter pixels represent foreground regions) is shown on the right. The first video was recorded during the day while the second one – at night. Since we don’t have the ground-truth annotations for these videos, it is not possible to compute numerical evaluation metrics, but the visual results demonstrate that BSUV-Net 2.0 can be used in real-world applications during both day and night. In particular, note that the stopped cars are correctly detected and flashing billboards are ignored thanks to spatio-temporal data augmentation methods used during training. Note that the visible compression distortions were not present in the original video to which BSUV-Net 2.0 was applied and are due to recompression by YouTube.
The full description of BSUV-Net 2.0 and a detailed ablation study can be found in our paper referenced below.
Source Code: The training code of BSUV-Net 2.0 is publicly available at github.com/ozantezcan/BSUV-Net-2.0.
Publications:
- M.O. Tezcan. P. Ishwar, and J. Konrad, “BSUV-Net 2.0: Spatio-temporal data augmentations for video-agnostic supervised background subtraction”, in IEEE Access, 2021.