RAPiD: Rotation-Aware People Detection in Overhead Fisheye Images
Team: Zhihao Duan, M. Ozan Tezcan, Hayato Nakamura, Prakash Ishwar, Janusz Konrad
Funding: Advanced Research Projects Agency – Energy (ARPA-E)
Status: Completed (2019-2020)
Background: Occupancy sensing is an enabling technology for smart buildings of the future; knowing where and how many people are in a building is key for saving energy, space management and security (e.g., fire, active shooter). In this work, we develop a fast people-detection algorithm for overhead fisheye images.
Summary: Our previous people-detection algorithm for fisheye images by Li et al. produced accurate results at very high computational complexity; even on a relatively small HABBOF dataset it required tens of GPU-hours during inference. The main reason for this is the fact that the algorithm applies YOLO (version 3) to each fisheye image up to 24 times. In this work, we propose a faster and accurate approach by designing an end-to-end neural network, which extends YOLO v3 to precisely handle human-body orientation in overhead fisheye images. Our fully-convolutional neural network directly regresses the angle of each bounding box using a periodic loss function, which accounts for angle periodicities. We show that our simple, yet effective method outperforms state-of-the-art results on three datasets: Mirror Worlds, HABBOF, and CEPDOF.
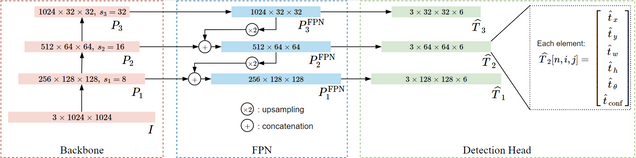
Technical Approach: RAPiD is a single-stage fully-convolutional neural network that predicts arbitrarily-rotated bounding boxes of people in a fisheye image. It extends the model proposed in YOLO, one of the most successful object detection algorithms for standard images. The network architecture diagram is shown below. In addition to predicting the center and size of a bounding box, RAPiD also predicts its angle. This is accomplished by a periodic loss function based on an extension of a common regression loss. This allows us to predict the exact rotation of each bounding box in an image without any assumptions and additional computational complexity. Unlike many previous methods, RAPiD is an end-to-end algorithm, so we can train or fine-tune its weights on annotated fisheye images. We show that such fine-tuning of a model trained on standard images significantly increases the performance. An additional aspect of this work, motivated by its focus on people detection, is the replacement of the common regression-based loss function used in multi-class object detection algorithms with single-class object detection. The inference speed of RAPiD is nearly identical to that of YOLO since it is applied to each image only once without the need for pre-/post-processing.
Datasets: Although there exist several datasets for people detection from overhead, fisheye images, either they are not annotated with rotated bounding boxes, such as in the Mirror Worlds dataset, or the number of frames and people are limited, such as in the HABBOF dataset. Therefore, we collected and labeled a new dataset named Challenging Events for Person Detection from Overhead Fisheye images (CEPDOF). The new dataset contains many more frames and human objects, and also includes challenging scenarios such as crowded rooms, various body poses, and low-light conditions, which are absent in other datasets. Furthermore, CEPDOF is annotated spatio-temporally, i.e., bounding boxes of the same person carry the same ID in consecutive frames, and thus can be also used for additional vision tasks using overhead, fisheye images, such as video-object tracking and human re-identification.
Since the original Mirror Worlds (MW) dataset is annotated only with axis-aligned bounding boxes that often do not fit tightly around people, we have manually annotated a subset of the MW dataset with rotated bounding-box labels, that we refer to as MW-R. For more details and to download both datasets, please refer to the links below.
- Challenging Events for Person Detection from Overhead Fisheye images (CEPDOF)
- Rotated Bounding-Box Annotations for Mirror Worlds Dataset (MW-R)
Experimental Results: The table below compares RAPiD with previous algorithms on three datasets: MW-R, HABBOF, and CEPDOF. Since there is no predefined train/test split in these three datasets, we cross-validate RAPiD on these datasets, i.e., two datasets are used for training and the remaining one for testing, and this is repeated so that each dataset is used once as the test set. For example, RAPiD is trained on MW-R + HABBOF, and tested on CEPDOF, and similarly for other permutations. Since neither Li et al. (see also this webpage) nor Tamura et al. algorithms are designed to be trained on rotated bounding boxes, we just trained them on COCO dataset as described in their papers. We use 0.3 as the confidence threshold for all the methods to calculate Precision, Recall, and F-measure. All methods are tested without test-time augmentation. Results are averaged over all videos in each dataset. We observe that RAPiD at 608×608-pixel resolution achieves both better performance and faster execution speed than the other two methods. RAPiD achieves even better performance when the input image resolution is raised to 1024×1024, but at the cost of a doubled inference time.

The table below shows the performance of RAPiD on each video in the CEPDOF dataset. We didn’t put this table in our paper due to the limited space. As can be seen from the table, our algorithm performs very well on normal light videos (Lunch meeting 1/2/3, Edge cases, and High activity) with Average Precision (AP) more than 90. However, low-light videos (All-off, IRfilter, and IRill) remain challenging.

The figure below shows the qualitative results of RAPiD at 1024×1024-pixel resolution applied to unseen images. From the quantitative and qualitative results, we conclude that RAPiD is robust to a wide range of real-world scenarios.


Source Code: RAPiD source code is available for non-commercial use after filling out the form below. If you publish any work reporting results using this source code, please cite the paper listed at the bottom of this page.
To access the download page, please complete the form below including the captcha.
RAPiD Download Form
Publications:
- Z. Duan, M.O. Tezcan, H. Nakamura, P. Ishwar and J. Konrad, “RAPiD: Rotation-aware people detection in overhead fisheye images”, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Omnidirectional Computer Vision in Research and Industry (OmniCV) Workshop, June 2020.