RAPiD-T: Leveraging Temporal Information for People Detection from Overhead Fisheye Cameras
Team: M. Ozan Tezcan, Prakash Ishwar, Janusz Konrad
Funding: Advanced Research Projects Agency – Energy (ARPA-E)
Status: Completed (2019-2022)
Background: The current people-detection algorithms for overhead fisheye cameras apply frame-wise inference ignoring temporal dependencies. Recent research on video-object detection has shown a significant performance boost by combining spatial and temporal information (e.g., REPP, FGFA, SELSA). We adopt this strategy for overhead fisheye videos and introduce 3 spatio-temporal extensions to RAPiD, the top-performing algorithm developed in our lab. We show that the improved versions of RAPiD significantly outperform state of the art on a recently published in-the-wild dataset, WEPDTOF.
Summary: Our previous people-detection algorithm for fisheye images by Duan et al., RAPiD, produced very successful results on three staged datasets, Mirror Worlds, HABBOF, and CEPDOF. However, when evaluated on our recent in-the-wild datasetet, WEPDTOF, RAPiD achieved ~72% AP50 and ~0.668 F-Score, far lower metrics than those for the staged datasets. The image below shows the predictions of RAPiD on a sample frame from WEPDTOF. The green bounding boxes show the correct detections of RAPiD, while the yellow ones show the missed detections. Clearly, the performance of RAPiD drops for challenging real-life scenarios such as camouflage, occlusions, etc. This drop is often due to intermittent misses and false detections that are difficult to remedy by purely spatial processing. Therefore, below we introduce 3 extensions to RAPiD that combine spatial and temporal information to boost the algorithm’s performance.

RAPiD+REPP: Robust and Efficient Post-Processing (REPP) is a post-processing method designed for object-detection algorithms that produce regular bounding boxes (aligned with image axes). It uses a learning-based similarity function to link bounding boxes in consecutive frames and produce the so-called object tubelets (known earlier as object tunnels). This is followed by a refinement step which smooths the confidence score, location and size of the bounding boxes within tubelets. This, effectively, increases the confidence scores of weaker detections and decreases those of stronger detections. RAPiD+REPP applies post-processing similar to that of REPP to bounding boxes detected by RAPiD. The post-processing consists of three steps. First, a similarity function is learned based on the following features for a pair of rotated bounding boxes detected by RAPiD (e.g., from consecutive frames):
- Euclidean distance between their centers,
- ratio of their widths and ratio of their heights,
- absolute difference between their angles,
- Intersection over Union (IoU) between them.
Our learning-based similarity function is trained on bounding boxes from CEPDOF using logistic regression. Then, bounding-box tubelets are formed using the obtained similarity function and the greedy algorithm described in REPP. Finally, a refinement step is applied to smooth out the confidence score, location, and size of the bounding boxes within tubelets. Details of the refinement step can be found in the REPP paper.
RAPiD+FGFA: Flow-Guided Feature Aggregation (FGFA) is an end-to-end video-object detection algorithm that aggregates feature maps computed from past, current, and future frames to aid object detection in the current frame. It consists of three parts. The first part is called “feature extraction network” and it takes a single frame as input and produces a feature map. The second part is called “flow-guided feature aggregation”. It uses optical flow to warp feature maps of past and future frames and produces their aggregate. Finally, the”detection network” predicts bounding boxes for the current frame from the output of the aggregation step. For more details, please refer to the FGFA paper. Following this approach, we introduce RAPiD+FGFA which applies temporal aggregation to each of the 3 feature maps generated by the “backbone” network of RAPiD. We use Farneback’s algorithm to compute optical flow since it outperforms FlowNet on overhead fisheye videos. We also introduce RAPiD+FA which applies feature aggregation with adaptive weights, but without feature warping.
Dataset: To evaluate in-the-wild performance of our new algorithms, we introduce a new benchmark dataset of in-the-Wild Events for People Detection and Tracking from Overhead Fisheye cameras (WEPDTOF). This dataset consists of 16 clips from 14 YouTube videos, each recorded in a different scene, with 1 to 35 people per frame and 188 person identities consistently labeled across time. Compared to the previous datasets, WEPDTOF has more than 10 times the number of distinct people, approximately 3 times the maximum number of people per frame, and double the number of scenes. For more details about WEPDTOF and to download, please refer to the link below.
Evaluation Metrics: We use average precision (AP) at 50% IoU, denoted as AP50, as the main evaluation metric. In addition to AP50, similarly to the MS COCO challenge , we report AP50 for small, medium and large bounding boxes denoted as APS50, APM50 and APL50, respectively. The figure below shows the histogram of bounding-box areas in WEPDTOF. We divide the bounding boxes into three groups: small (area ≤ 1,200), medium (1,200 < area ≤ 8,000) and large (8,000 < area) based on their areas normalized to image size of 1,024×1,024. Then, we calculate APS50 between small bounding-box annotations and small bounding-box detections, and similarly for APM50 and APL50. 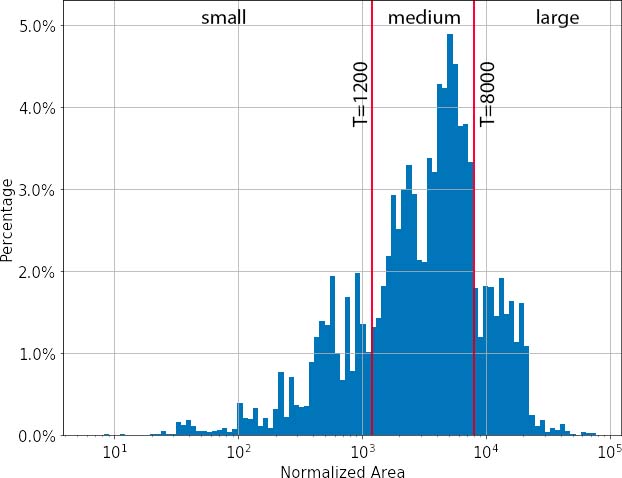
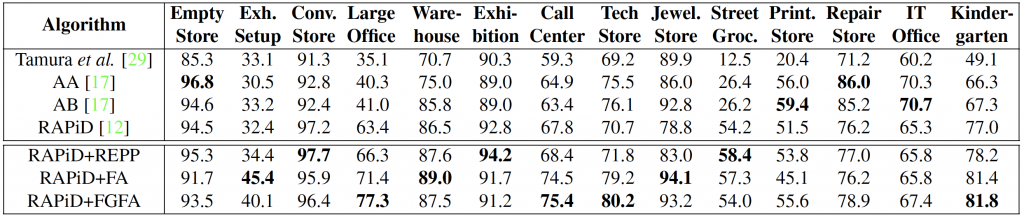
The table below shows the number of bounding-box annotations from these 3 categories for each video of WEPDTOF. We compute the macro-average of the per-video results for the videos with at least 100 annotations in that category (e.g., “Street Grocery” is not used for APS50 and APM50).

Experimental Results: The table below compares the performance of the proposed algorithms with state of the art on WEPDTOF. All algorithms are trained on MS COCO dataset for 100,000 iterations. RAPiD and its variants are fine-tuned on the combination of MW-R, HABBOF and CEPDOF for 5,000 iterations. Since AA, AB and Tamura et al. are not designed to be trained using rotated bounding boxes, fine-tuning on fisheye datasets is not possible. During inference, we use an input resolution of 1,024x,024, however during training we use 608×608 due to memory limitations. In RAPiD+FA and RAPID+FGFA, we use the feature maps of 11 consecutive frames to predict the bounding boxes of the middle frame. In all algorithms, we perform 2-fold cross-validation on WEPTDOF to first find the best-performing network weights on the validation set in terms of AP50, and then to tune the confidence threshold in order to maximize the F-Score. The proposed extensions of RAPiD achieve 2-5%-point better AP50 score than the original RAPiD. This demonstrates the importance of temporal information for people detection.
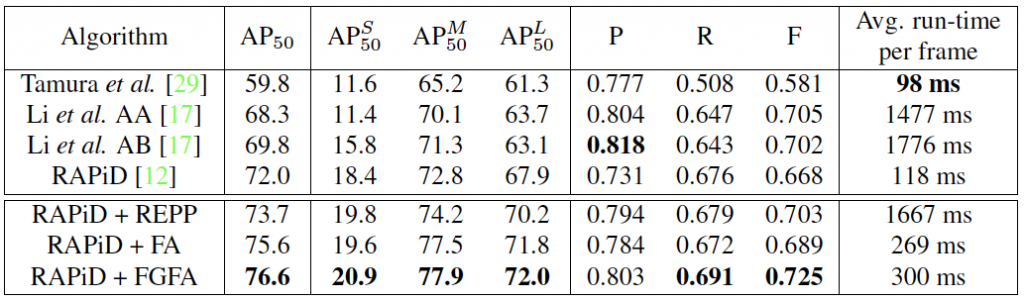
In particular, REPP improves the bounding boxes produced by RAPiD by changing their confidence scores, locations and sizes, but does not introduce new detections that are not produced by RAPiD. Thus, its performance gain is limited. By using an end-to-end integration of the temporal information, RAPiD+FA outperforms RAPiD+REPP in terms of AP50, but it is still outperformed in terms of the F-Score. RAPiD+FGFA outperforms both of these extensions in terms of all of the metrics with help from optical flow.
The performance gains of the proposed extensions come with a trade-off in terms of efficiency. When applied to bounding boxes aligned with image axes, REPP is proven to be very efficient with just a few milliseconds of extra computing time per frame. During inference, REPP computes IoU between all pairs of bounding-box predictions in consecutive frames. While this computation is efficient for bounding boxes aligned with image axes, it requires computationally-expensive geometric libraries for rotated bounding boxes thus making it inefficient.
Among all of the compared algorithms, APS50 is 4-7 times lower than APM50 and APL50 . Both MS COCO and fisheye people-detection datasets used for training are very limited in terms of small bounding boxes and this makes it challenging for learning-based algorithms to predict small bounding boxes. Clearly, this is an open research direction for people-detection algorithms from overhead fisheye cameras.
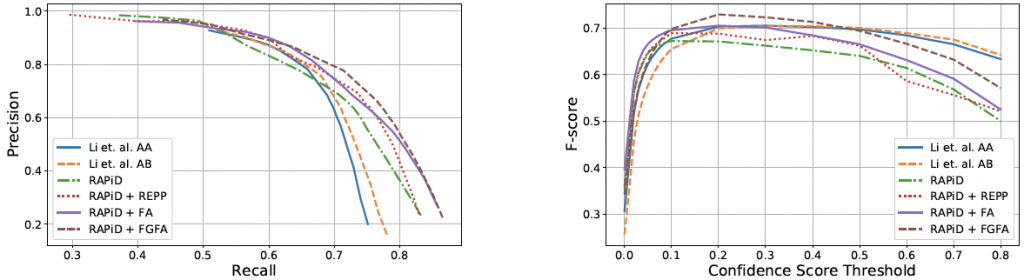
The performance trade-off plots below show a significant performance trade-off between spatial-only RAPiD and the AA and AB algorithms. Although RAPiD produces a higher area under the PR curve, the AA and AB algorithms perform better than RAPiD for high confidence-score thresholds suggesting that RAPiD produces bounding boxes with smaller confidence scores. This is likely due to the fact that the AA and AB algorithms compute bounding-box predictions in overlapped windows extracted from the same image and combine these results in a post-processing step. Thus, they can analyze the same person at multiple orientations which may boost the confidence score of the detection. Note, however, that RAPiD is over 10 times faster than AA and AB. The best F-Score achieved by RAPiD+FGFA outperforms the one achieved by AA and AB. However, AA and AB still outperform the spatio-temporal extensions of RAPiD for high confidence-score thresholds.
The figure below shows sample results produced by RAPiD and its spatio-temporal extensions applied to sample video frames from WEPDTOF. The correct detections are shown as green bounding boxes, missed detections as yellow bounding boxes and false detections as red bounding boxes. Clearly, leveraging temporal information improves the performance on some of the real-life challenges such as severe camouflage (“Exhibition Setup”) and very small body projections (“Tech Store” and “Warehouse”). In the “Tech Store” result, RAPiD produced two false detections in the center of the frame. One of them was corrected by all three proposed extensions and the other by two of them. Usually, this kind of a false detection happens in RAPiD with a low confidence score. In most frames, the score is below a set threshold and no person detection occurs. However, in some frames, the confidence score exceeds the set threshold resulting in intermittent false detections. The spatio-temporal versions of RAPiD help smooth out the confidence score temporally thus reducing the chance of a false detection. An analogous observation can be made with respect to missed detections (false negatives) in “Exhibition Setup” and “Warehouse”.

The table below shows per-video AP50 scores of the reported algorithms on WEPDTOF. Although spatio-temporal algorithms outperform the spatial-only algorithms for most of the videos, there is no single best algorithm for all the videos. Even the improved scores of the reported algorithms are not satisfactory for videos with tiny projected bodies at field-of-view periphery (e.g., “Exhibition Setup”), distorted image aspect ratio (e.g., “Street Grocery”), and strong camouflage (e.g., “Printing Store”). We believe the performance on these challenges can be further improved by developing algorithms that address them directly (e.g., data augmentation to mimic these challenges in the training set).
The videos below show qualitative results of the best performing algorithm, RAPiD+FGFA, on two in-the-wild and unseen videos. Clearly, RAPiD+FGFA is robust to a wide range of real-world scenarios.
Source Code: The source code of RAPiD+REPP, RAPiD+FA and RAPiD+FGFA algorithms is available for non-commercial use after filling out the form below. If you publish any work reporting results using this source code or the WEPDTOF dataset, please cite the paper listed at the bottom of this page.
To access the download page, please complete the form below including the captcha.
RAPiD-T Download Form
Publications:
- M.O. Tezcan, Z. Duan, M. Cokbas, P. Ishwar, and J. Konrad, “WEPDTOF: A dataset and benchmark algorithms for in-the-wild people detection and tracking from overhead fisheye cameras” in Proc. IEEE/CVF Winter Conf. on Applications of Computer Vision (WACV), 2022.